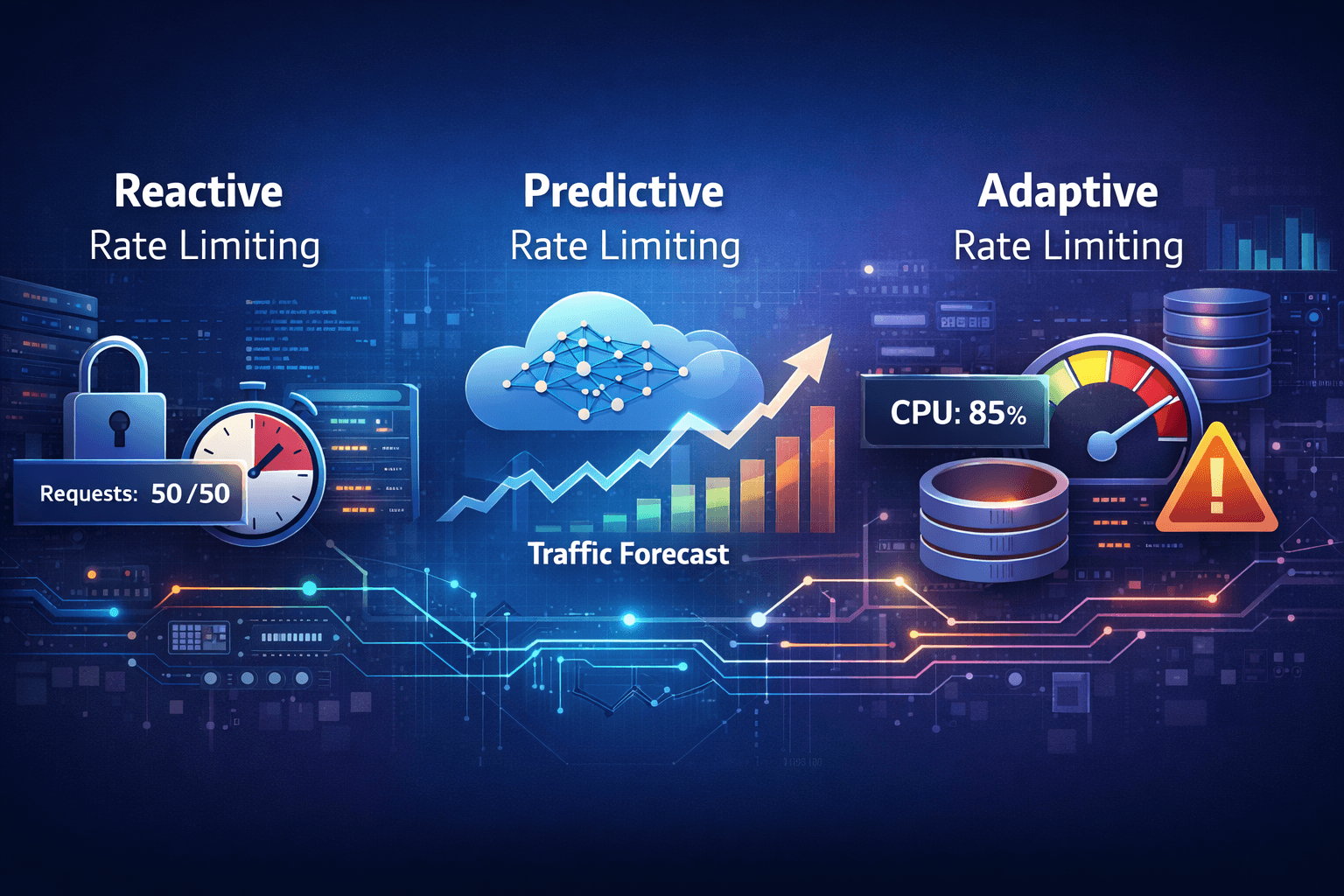
Reactive vs Predictive vs Adaptive Rate Limiting
👋Hi, my name is Siddhant.
👩💻I am a Software Engineer. I am passionate about technology, and coding. ✍I also like to read and write about technology and productivity.
In my free time, I play guitar🎸 and also like to play badminton🏸.
Every distributed system eventually faces this question:
How many requests can we safely handle?
Rate limiting is often treated as a simple middleware feature — add a token bucket, set 100 requests/minute, and move on.
But in production systems — especially those running on Kubernetes, backed by databases like RDS, and serving real users — rate limiting becomes a system design decision, not just an API configuration.
In this article, we’ll break down:
Reactive rate limiting
Predictive rate limiting
Adaptive rate limiting
How they differ
What production systems actually use
Why Rate Limiting Exists
Rate limiting is not just about stopping abuse.
It exists to:
Protect infrastructure
Prevent cascading failures
Maintain latency SLOs
Protect downstream dependencies (DB, cache, third-party APIs)
Ensure fairness across users
If your system can safely handle 50 requests per second, and suddenly receives 200, something will fail:
CPU saturates
DB connections exhaust
Latency spikes
Timeouts cascade
Retry storms begin
Good rate limiting prevents that chain reaction.
1️⃣ Reactive Rate Limiting (The Foundation)
What It Is
Reactive rate limiting enforces limits after requests arrive.
It doesn’t predict anything.
It simply checks counters and decides.
Request → Check counter → Allow or Reject
Common Algorithms
Fixed Window
Sliding Window
Token Bucket
Leaky Bucket
These are deterministic and rule-based.
Example:
If limit = 50 RPS:
The 51st request gets rejected.
No forecasting. No adaptation. Just enforcement.
Strengths
Simple to implement
Easy to reason about
Predictable behavior
Low operational complexity
Perfect for:
Internal APIs
Early-stage products
Controlled traffic environments
Weaknesses
Doesn’t anticipate spikes
Can cause abrupt throttling
Doesn’t consider system health
Treats all requests equally
If traffic suddenly doubles, reactive systems only respond once limits are breached.
They don’t prepare.
2️⃣ Predictive Rate Limiting (Anticipating Load)
What It Is
Predictive rate limiting uses historical traffic data to forecast near-future demand and adjust limits proactively.
Instead of asking:
“Are we overloaded right now?”
It asks:
“Will we be overloaded soon?”
Example Scenario
Historical data shows:
Traffic spikes every weekday at 9 AM
Friday evenings see 2x normal traffic
Product launches cause predictable bursts
A predictive system can:
Increase pod replicas before the spike
Adjust token bucket size
Pre-warm DB connections
Scale caches
Instead of reacting to overload, it prepares for it.
Important Rule:
Predicted demand must never exceed safe system capacity.
The safe formula is:
final_limit = min(predicted_demand, safe_capacity)
Where:
safe_capacitycomes from load testing and SLO analysispredicted_demandcomes from time-series modeling
If your system can safely handle 50 RPS and the model predicts 60 RPS demand, you either:
Scale capacity to 80 RPS
OR
Cap limit at 50
Prediction never overrides infrastructure reality.
Strengths
Smoother user experience
Fewer sudden throttles
Better alignment with autoscaling
Good for seasonal traffic
Weaknesses
Requires high-quality historical data
Model drift risk
Operational complexity
Overengineering for small systems
Best suited for:
Public SaaS APIs
Large-scale platforms
Systems with strong seasonality
3️⃣ Adaptive Rate Limiting (Self-Protecting Systems)
What It Is
Adaptive rate limiting adjusts limits based on real-time system health, not forecasts.
It monitors:
CPU usage
Memory pressure
DB connection pool utilization
P99 latency
Error rate
Instead of asking:
“How much traffic is coming?”
It asks:
“How stressed is the system right now?”
Example
If:
CPU > 85%
DB pool utilization > 90%
Latency SLO violated
The system dynamically reduces rate limits.
It actively protects itself.
Conceptual Control Formula
limit = f(system_health_metrics)
For example:
if latency > threshold:
reduce limit by 20%
This prevents cascading failures.
Strengths
Automatically protects downstream systems
Reduces failure amplification
Prevents retry storms
Ideal for microservices architectures
Weaknesses
Can oscillate if poorly tuned
Harder to debug than static systems
Requires good observability
Adaptive systems require strong monitoring.
Without metrics, they’re blind.
A Quick Comparison
| Feature | Reactive | Predictive | Adaptive |
| Uses history | ❌ | ✅ | ❌ |
| Uses real-time health | ❌ | Sometimes | ✅ |
| Forecasts spikes | ❌ | ✅ | ❌ |
| Protects during overload | Limited | Indirect | Strong |
| Complexity | Low | High | Medium |
What Production Systems Actually Do
Most large systems do not pick one approach.
They combine them.
A realistic production model looks like this:
Reactive (base rule)
+ Adaptive (system protection)
+ Predictive (traffic forecasting)
Final decision formula:
final_limit = min(
safe_capacity,
predicted_traffic,
adaptive_health_limit
)
This gives:
Hard safety guardrails
Intelligent anticipation
Real-time protection
A Real Backend Example
Imagine a Kubernetes-based API backed by a relational database.
Your true bottleneck isn’t CPU.
It’s:
DB connection pool exhaustion
Lock contention
I/O saturation
If you only limit by RPS, you may still overload the database.
Better approach:
Reactive RPS limiter
Concurrency-based limiter (limit in-flight DB queries)
Adaptive throttling when latency spikes
Rate limiting must reflect real bottlenecks — not just request count.
Final Thoughts
Reactive rate limiting protects against abuse.
Predictive rate limiting prepares for growth.
Adaptive rate limiting protects the system itself.